Breaking Down Unmute, Our 3rd Place Entry at the Gemini 3 Hackathon
12 Jan 2026 - 6 min read

I first stumbled upon Singapore Sign Language while I was looking for electives at NTU. While I was never able to take the module myself, NTU’s excellent website allowed me to learn more about the history of Sign Language in Singapore. In particular, I was impressed by their extensive recording and documentation of more than a thousand unique signs.
While brainstorming for the Gemini 3 Hackathon, Anurag, Vaishnav, and I decided to leverage this dataset to build a real-time translation application that maps text to sequences of signs and presents them to the user via an avatar. Seven hours later, our entry was shortlisted, and we were pitching Unmute to the judges. This post covers how we built our application, the challenges we faced, and how we plan to extend it.
1. Dataset Preparation
1.1. Web Scraping
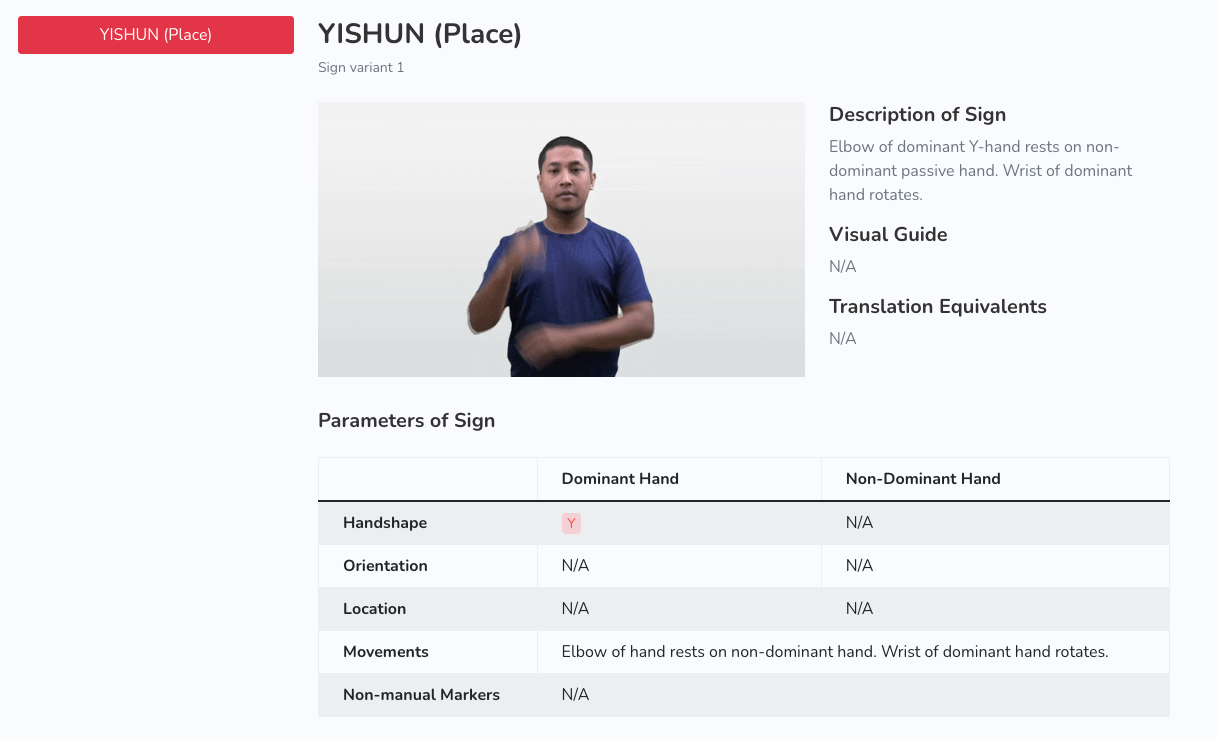
Using selenium and BeautifulSoup, we wrote a scraper to create a local copy of the Sign Bank dataset. A GIF and JSON metadata file was saved for each sign in the dataset, as shown below.

{
"sign": "abuse",
"gif_url": "https://blogs.ntu.edu.sg/sgslsignbank/files/formidable/3/2025-02-03/2.-Abuse-095bde.gif",
"description": null,
"visual_guide": "N/A",
"translation_equivalents": "N/A",
"parameters": {
"Handshape": {
"Dominant Hand": "S",
"Non-Dominant Hand": "1"
},
"Orientation": {
"Dominant Hand": "Palm-down",
"Non-Dominant Hand": "Palm-out"
},
"Location": {
"Dominant Hand": "Neutral space",
"Non-Dominant Hand": "Neutral space"
},
"Movements": {
"Dominant Hand": "N/A",
"Non-Dominant Hand": "N/A"
},
"Non-manual Markers": {
"Dominant Hand": "N/A",
"Non-Dominant Hand": "N/A"
}
},
"units": [
{
"step": "Step 1",
"filename": "units/1.png"
},
{
"step": "Step 2",
"filename": "units/2.png"
},
{
"step": "Step 3",
"filename": "units/3.png"
},
{
"step": "Step 4",
"filename": "units/4.png"
}
],
"description_of_sign": "Dominant hand S waves back and forth behind non-dominant 1-hand."
}
1.2 Pose Estimation with MediaPipe
To fulfill our requirement of creating 3D avatars, we used the MediaPipe package to detect hand and pose landmarks for each sign in our dataset.
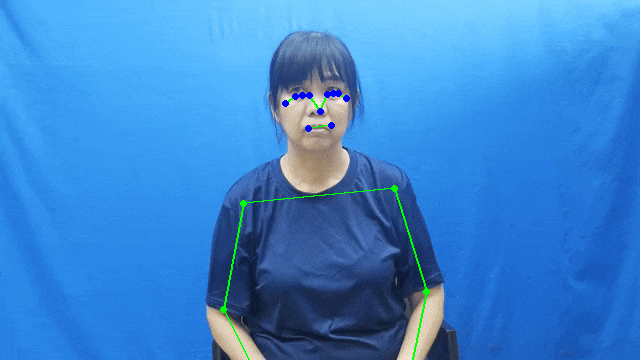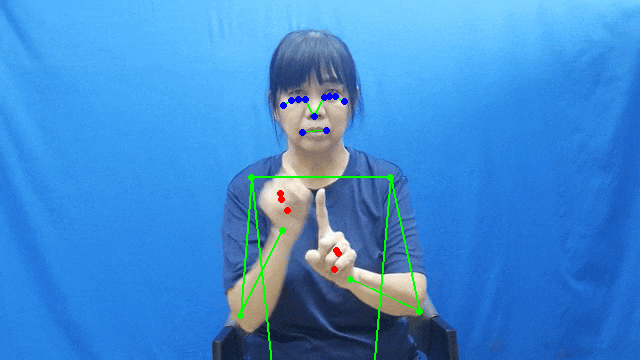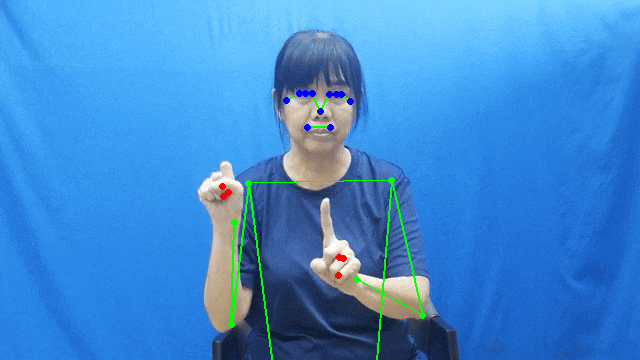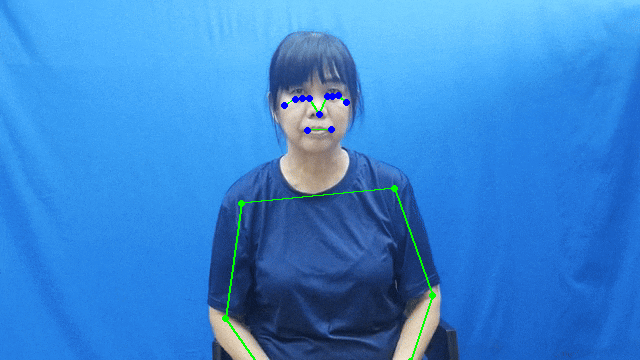

The output format for each model is as follows:
- Hand landmarks: 21 keypoints per hand
- Pose landmarks: 33 body keypoints
To account for variances in the FPS and duration of the GIFs in our dataset, we applied zero padding to the detected sequences. The processed coordinates are stored in .pkl files to be served by our backend.
2. Building the Text-to-Sign Pipeline
Vocabulary Construction
With all the data collected and processed for our application, we looked at orchestration: how can we convert spoken or written text to sequences of signs? In order to do this accurately, we needed to create a consistent vocabulary of sign language tokens that can be used by an LLM to recreate a full text sentence into sequences of signs.
To do this, we normalized all the scraped text labels into a consistent format by removing non-alphanumeric characters, replacing spaces and hyphens with underscores, and converting all text to uppercase. The result is a token-to-sign dictionary that maps our normalized tokens to our GIF dataset, a snippet of which is shown below.
{
"token_to_sign": {
"SUPPER": "supper",
"COLD_A": "cold-a",
"WRITE": "write",
"COCHLEAR_IMPLANT_MEDICAL": "cochlear_implant-medical",
"SHARE_VERB": "share-verb"
}
}
Additionally, we created an aliases.json file containing a dictionary which maps common variations of words to our normalized tokens. We will look to further extend this file to improve the speed of our translation workflow without relying excessively on LLMs.
{
"PLS": "PLEASE",
"THX": "THANKS",
"THANK_YOU": "THANKS",
"SGP": "SINGAPORE_PLACE_A",
"SG": "SINGAPORE_PLACE_A",
"MUM": "MOTHER",
"DAD": "FATHER",
"BRO": "BROTHER",
"SIS": "SISTER"
}
The resulting vocab.json and aliases.json files serve as the foundation for our text-to-sign pipeline.
Translation with Gemini
Given the time constraints of the hackathon and the fact that our generated vocabulary set was only around a thousand words, for a proof-of-concept, we provided the complete vocabulary list into our prompt and instructed Gemini to output a sequence of normalized tokens known as glosses.
prompt = f"""
You are a multilingual Singapore Sign Language (SGSL) translator.
Your task is to translate text from ANY language into SGSL Gloss tokens.
{language_instructions}
Important Constraints:
1. SGSL often uses Subject-Object-Verb (SOV) or Topic-Comment structure, different from English SVO.
2. You MUST use ONLY words from the provided vocabulary list below.
3. For words not in vocabulary, try synonyms (e.g., "MUM" -> "MOTHER", "Mama" -> "MOTHER").
4. Consider cultural context - SGSL reflects Singapore's multilingual environment.
5. For Chinese input: Consider tone and context; map to appropriate SGSL concepts.
6. For Malay/Tamil input: Translate meaningfully, not word-by-word.
7. If key concepts cannot be translated, include them in 'unmatched' array.
8. Preserve the semantic meaning and intent of the original text.
Vocabulary (use ONLY these tokens):
[{token_str}]
Input Text: "{text}"
Output JSON format strictly:
{
"gloss": ["TOKEN1", "TOKEN2", ...],
"unmatched": ["word1", ...],
"notes": "Brief explanation of translation choices and detected language",
"detected_language": "language code if auto-detected"
}
"""
Using the gloss array output by Gemini, we subsequently look up the GIFs and MediaPipe poses and serve them to the client for rendering.
Using Gemini also allowed us to easily integrate multilingual and multimodal capabilities into our application, allowing users to interact with Unmute in any language supported by the Gemini API.
Visualizing Results
Due to time constraints, we built a single-page web UI that interfaces with our backend and visualizes the following results:
- A reference GIF from the Sign Bank dataset.
- A
Three.jsskeleton rendered usingMediaPipepose estimation landmarks.
3. Conclusion and Future Directions
Getting shortlisted from 200 participants, pitching our application, and finishing third was a surreal experience. I would like to take this opportunity to extend my heartfelt gratitude to Google DeepMind, Agrim, Evan, Ivan, Manikantan, Natalie, Sherry and Thor for organizing this event, judging submissions, and nurturing the rapidly growing builder scene in Singapore.
With that being said, we’re far from finished with building on this idea. Our team knows that we have barely scratched the surface of what this dataset and application are capable of. We are planning to make significant improvements:
- Improving our UI/UX to have smoother animations and a more polished end-user experience
- Enhancing translation accuracy and improving sentence-level planning
- Attempting to tackle sign-to-text translation to close the loop and make this a two-way solution.
We believe that this application has the potential to bridge communication gaps in Singapore. If you are working in accessibility, sign linguistics, or multimodal AI and would like to collaborate or share feedback, please reach out. If you would like to try Unmute yourself, stay tuned! We are working on deploying it to make it publicly accessible.